Monday, December 10, 2012
My Very First Guest Post
I met someone at the PASS Summit this year who really pushed past her fears to meet a lot of people and make an impact. Andrea Allred. As a tribute to her bravery, I have submitted a guest post over on her blog specifically about dealing with your fears and not letting them stand in your way. Swing over to her blog (www.royalsql.com) and check out her awesome posts.
My guest post can be found here: http://www.royalsql.com/2012/12/10/fear-is-a-part-of-life-by-matt-slocum/
SQLFamily is awesome!
Wednesday, December 5, 2012
How to Downgrade SQL Server Editions
I recently ran into an issue where the production VM template (containing
Enterprise Edition of SQL Server 2008 R2) was used to deploy new SQL Server VMs
for Engineering development (and thus should be the Developer Edition of SQL
Server 2008 R2). This is not a supported
path by Microsoft, thus a more creative approach needs to be taken in order to
accomplish this task.
In order to complete this task, uninstalling the higher edition of SQL
and reinstalling the correct edition is required. I was able to work out the following process
that helped to ease the pain of the downgrade.
I have used this process to downgrade Enterprise Edition to both
Developer Edition and Standard Edition, but it should also work for any other
lower Edition of SQL Server (Web, Workgroup, etc…)
I started by verifying the integrity (DBCC CHECKDB) and creating fresh
backups of all DBs (including system DBs).
I then created scripts to recreate all of the following (in case the
process failed at any point):
·
Logins (including roles) – contained in Master
database
o
I used sp_help_revlogin, which works great for
recreating the logins with the existing password, but unfortunately it does not
script out the role membership (I scripted that manually). For those that are curious, the password is
hashed in the script, so you can’t use sp_help_revlogin to look up/hack a login
password.
·
Jobs – contained in MSDB database
o
I had job creation scripts for setting up the
server in the first place, but you can select the Jobs folder in the Object
Explorer pane in SSMS and then right-click each job. Just select Script Job as… > CREATE To > New Query Editor
Window
·
SSIS Packages – contained in MSDB database
o
Restoring the MSDB database should recover your
SSIS Packages, but you may want to export them through Integration Services,
just to be certain to preserve your hard work.
Note: The build number must match exactly for this process to succeed. I was able to apply SP2 for SQL 2008 R2 (SP2 for SQL 2008 R2 results in build 4000 - 10.50.4000) before starting the process to make things easier after the install (then I don't have to track down what Cumulative Updates and/or Security Updates are applied to the current instance of SQL).
Next, I stopped all SQL Server services and created a folder on the
Desktop (called System DBs). I copied in
the MDF and LDF files for the Master, MSDB, and Model (as we had customized Model)
databases for the Enterprise Edition installation of SQL Server.
With all the ground work in place, I then uninstalled all MSSQLSERVER
features to remove Enterprise Edition (I grabbed a screen shot of the Select Features
screen while I was uninstalling so that I could be certain to install the
correct features when reinstalling).
Uninstalling the Shared Features is not necessary, and will only make
the process take longer.
I then installed Standard Edition to the same folder as the previous
(Enterprise) edition. I also applied the
correct service pack to SQL Server (to bring the build up to the same as the previous Edition). Installing SQL Server to the same folder
will overwrite all existing System DBs, but your User DBs will remain
unscathed.
At this point in the process is where I tried to add some awesome
sauce.
Instead of attempting to restore master (which can be a royal pain),
model, and msdb; I merely stopped all SQL services. I then created a new folder on the Desktop
(called New System DBs) and moved out the current MDF and LDF files for the Master,
Model and MSDB databases. Then I copied
in the MDF and LDF files for the previous installation of the Master, Model and
MSDB databases and started the SQL services again.
This worked perfectly! I was
presented with all my databases, logins (with the appropriate roles), jobs, SSIS packages, etc...
Summary:
1. Verify integrity of all DBs (DBCC CHECKDB)
2. Make backups of all DBs (including system DBs)
3. Make scripts to be able to attach DB and recreate logins (including
roles), jobs, SSIS packages, etc... (just in case the overall process breaks)
4. Make note of the current Service Pack for SQL Server and the path(s)
that SQL Server is installed to.
5. Stop all SQL Services
6. Make copies of the MDF and LDF files for Master and MSDB (Model too
if you've customized it like I have) to System DBs folder
7. Uninstall SQL Server Enterprise Edition (all Features under
MSSQLSERVER need to be removed and be sure to make note of the Features you're
uninstalling)
8. Install SQL Server Standard Edition (or the Edition you're trying to
downgrade to - i.e. Web, Developer, etc...) making sure to install the same
features for SQL Server
9. Install the same Service Pack as was previously installed
10. Stop all SQL Services
11. Move current MDF and LDF files for Master and MSDB (Model too if
customized) out to New System DBs folder
12. Copy in MDF and LDF files for Master and MSDB (and Model if
customized) from previous installation
13. Start SQL Server services
I hope this process helps you if you find yourself in the same situation.
Thursday, November 8, 2012
My PASS Summit 2012 Experience - Day 2 Keynote (LiveBlog)
Thursday is Women In Technology day at the PASS Summit. This year I was able to wear a kilt to show support for the fairer gender.
The keynote started off with an overall PASS status update. Emphasis was given to the community, and how you can do much in the community without huge financial resources at your disposal.
Tomas LaRock stepped up and announced some additional awards being added to the PASS lineup. Jen Stirrup was awarded the PASSion award, and she totally deserves it for her contributions to recognizing Women In Technology.
PASS Summit 2013 was mentioned. It will be held October 15-18 in Charlotte, NC. www.sqlpass.org/summit/2013/
Quentin Clarke (Microsoft Corporate Vice President, Database Systems Group) spoke on data analysis and how businesses can use that data to market their business. This poses new challenges and problems when trying to analyze that data in a more real-time manner.
A large package shipping company was mentioned, and the analytics that they perform to generate additional revenue by analyzing the contents of their data warehouse. The data life-cycle was discussed and demoed. Effective use of the data requires analysis and collaboration between multiple departments/companies to take full advantage of the advantages that proper analysis can reap.
Analyzing data from a movie theater company's data warehouse was demoed (utilizing PowerView). There was a mixed response as most DBAs and straight up developers were not incredibly impressed or interested. Karen Lopez tweeted that big data might not be interesting, but it is inevitable and that we need to at least be aware of the technology and how to work with it. As a DBA, I'm likely not going to be using Excel very frequently. If the demos could cover more information as to how things work under-the-hood, a lot more interest would be garnished. I think that's why Dr. DeWitt was so insanely popular last year.
The ability to add Azure as an Availability Replica was an awesome feature that was shown off toward the end of the demo. The demo ended on a high note as more functions and features were demoed.
I'm really looking forward to Dr. DeWitt's session tomorrow. What a brilliant man!
Wednesday, November 7, 2012
My PASS Summit 2012 Experience - Day 1 Keynote (LiveBlog)
Bill Graziano opened the day with a PASS status update and Summit overview. Connect, Share, and Learn is still the mantra of PASS. Community is of critical importance. No one can know everything, but together we can accomplish anything. Bill recognized many of the community volunteers. It was a great opportunity to realize and acknowledge the value of those that contribute to the community.
A new user group website was announced with additional and more valuable tools. These tools are designed to ease chapter management and administration. As a chapter leader, this excites me greatly.
A PASS BI conference in Chicago (at the Sheraton Chicago Hotel and Towers) was announced, April 10-12, 2013. The BI arena is growing rapidly and a dedicated conference is awesome.
It's an exciting time to be involved in PASS. PASS is growing (over 127,000 members) and is becoming much more globally focused. International growth has been tremendous. 57 countries are represented and additional growth opportunities are actively being developed.
Ted Summers (Corporate VP of Microsoft) presented the keynote. Microsoft is extremely excited about the release of SQL Server 2012. The release of SP1 for SQL Server 2012 was announced and was released today. I'm very excited about that as it addresses a performance issue that I had when testing SQL Server 2012.
Big/non-relational data (including, but not limited to, Hadoop) is still a big focus for Microsoft. Data storage requirements are only going to continue to increase in the future, so dealing with larger and larger amounts of data will continue to garnish attention.
In-memory technology was discussed and it was announced will be a feature in the next major version of SQL Server (codename: Hekaton). The technology was demoed and you can actually pin an entire table (including indexes and table structures) into RAM (the demo initially yielded a 5x gain in performance). You can also recompile SPROCs to run native in memory (in combination with in-memory configured for the table, this yielded nearly a 30x gain in performance in the demo). Included is a tool that examines performance and recommends tables and SPROCs for in memory optimization. No code or hardware changes were needed to reap huge benefits.
Performance gains of an in memory column store index was also discussed.
Heketon makes SQL incredibly fast ("wicked fast") and since it's merely an enhancement to SQL Server, if you know SQL Server, you know Heketon.
Additional optimizations to the parallel data warehouse have yielded massive performance improvements in that arena as well.
An updated query processor was announced. PolyBase handles queries from multiple sources, including local and cloud sources. This allows you to use standard T-SQL code to query Hadoop and other non-relational databases. You can even JOIN between relational and non-relational data. This will also be included in the next major version of SQL.
BI enhancements were announced. Excel 2013 is now a complete BI tool. PowerView has been integrated into Excel to provide exceptional BI functionality. Full interactive maps were demoed directly within Excel.
Overall, the keynote on Wednesday was very exciting for the SQL Server professional. I eagerly anticipate the next major release of SQL Server.
Wednesday, August 29, 2012
SQL Server Service crash after Service Pack Install
A tough lesson regarding why you should always keep the configured default Data and Log paths updated in SQL Server.
At my company, our virtual infrastructure is growing and changing rapidly. As a result the configuration of our SQL Servers is changing also. This results in additional drives and drive letter changes for our SQL servers.
Unfortunately, if the default Data and Log paths are not updated when the drive letters change, there will be errors after installing (or uninstalling) a Service Pack or Cumulative Update. The GUI portion of the install will complete successfully, but there are updates that occur on the initial service start after the GUI portion of the install is complete. One update that occurs that that initial service start is database upgrades. If your default paths for data and log files are not correct (in my case the drives referenced no longer existed), the upgrade of the master database will fail and the SQL Server service will crash.
In a production setting, this can induce fear, panic, and mass hysteria (or at the very least mass Google searching, which is likely how you arrived at this page to begin with). However, the solution is pretty simple as the default paths are stored in the Windows registry.
Launch Registry Editor (regedit.exe) and navigate to the following section of the registry tree:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\{SQL Version}\MSSQLServer
Note: If you are running a 32-bit version of SQL Server on a 64-bit OS, you'll need to navigate to the Wow6432Node tree (HKEY_LOCAL_MACHINE\Software\Wow6432Node\Microsoft\Microsoft SQL Server\{SQL Version}\MSSQLServer)
SQL 2000 {SQL Version} = MSSQLServer
SQL 2005 {SQL Version} = MSSQL.1
SQL 2008 {SQL Version} = MSSQL10.MSSQLSERVER
SQL 2008 R2 {SQL Version} = MSSQL10_50.MSSQLSERVER
SQL 2012 {SQL Version} = MSSQL11.MSSQLSERVER
Then update the paths specified in the following keys:
DefaultData
DefaultLogs
Once the paths are correct, the master database upgrade will complete successfully (as SQL Server will be able to create the temporary files in the default paths) and once all other system and user DBs are upgraded you should be back up and running.
Note: The database upgrades will take some time if you have a lot of user DBs, but you can monitor the ERRORLOG to observe the progress.
Here is the appropriate snippet from my log for the failure on the data file:
2012-08-29 08:45:43.39 spid7s Error: 5133, Severity: 16, State: 1.
2012-08-29 08:45:43.39 spid7s Directory lookup for the file "G:\MSSQL\Data\temp_MS_AgentSigningCertificate_database.mdf" failed with the operating system error 3(The system cannot find the path specified.).
2012-08-29 08:45:43.39 spid7s Error: 1802, Severity: 16, State: 1.
2012-08-29 08:45:43.39 spid7s CREATE DATABASE failed. Some file names listed could not be created. Check related errors.
2012-08-29 08:45:43.39 spid7s Error: 912, Severity: 21, State: 2.
2012-08-29 08:45:43.39 spid7s Script level upgrade for database 'master' failed because upgrade step 'sqlagent100_msdb_upgrade.sql' encountered error 598, state 1, severity 25. This is a serious error condition which might interfere with regular operation and the database will be taken offline. If the error happened during upgrade of the 'master' database, it will prevent the entire SQL Server instance from starting. Examine the previous errorlog entries for errors, take the appropriate corrective actions and re-start the database so that the script upgrade steps run to completion.
2012-08-29 08:45:43.39 spid7s Error: 3417, Severity: 21, State: 3.
2012-08-29 08:45:43.39 spid7s Cannot recover the master database. SQL Server is unable to run. Restore master from a full backup, repair it, or rebuild it. For more information about how to rebuild the master database, see SQL Server Books Online.
2012-08-29 08:45:43.39 spid7s SQL Trace was stopped due to server shutdown. Trace ID = '1'. This is an informational message only; no user action is required.
At my company, our virtual infrastructure is growing and changing rapidly. As a result the configuration of our SQL Servers is changing also. This results in additional drives and drive letter changes for our SQL servers.
Unfortunately, if the default Data and Log paths are not updated when the drive letters change, there will be errors after installing (or uninstalling) a Service Pack or Cumulative Update. The GUI portion of the install will complete successfully, but there are updates that occur on the initial service start after the GUI portion of the install is complete. One update that occurs that that initial service start is database upgrades. If your default paths for data and log files are not correct (in my case the drives referenced no longer existed), the upgrade of the master database will fail and the SQL Server service will crash.
In a production setting, this can induce fear, panic, and mass hysteria (or at the very least mass Google searching, which is likely how you arrived at this page to begin with). However, the solution is pretty simple as the default paths are stored in the Windows registry.
Launch Registry Editor (regedit.exe) and navigate to the following section of the registry tree:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\{SQL Version}\MSSQLServer
Note: If you are running a 32-bit version of SQL Server on a 64-bit OS, you'll need to navigate to the Wow6432Node tree (HKEY_LOCAL_MACHINE\Software\Wow6432Node\Microsoft\Microsoft SQL Server\{SQL Version}\MSSQLServer)
SQL 2000 {SQL Version} = MSSQLServer
SQL 2005 {SQL Version} = MSSQL.1
SQL 2008 {SQL Version} = MSSQL10.MSSQLSERVER
SQL 2008 R2 {SQL Version} = MSSQL10_50.MSSQLSERVER
SQL 2012 {SQL Version} = MSSQL11.MSSQLSERVER
Then update the paths specified in the following keys:
DefaultData
DefaultLogs
Once the paths are correct, the master database upgrade will complete successfully (as SQL Server will be able to create the temporary files in the default paths) and once all other system and user DBs are upgraded you should be back up and running.
Note: The database upgrades will take some time if you have a lot of user DBs, but you can monitor the ERRORLOG to observe the progress.
Here is the appropriate snippet from my log for the failure on the data file:
2012-08-29 08:45:43.39 spid7s Error: 5133, Severity: 16, State: 1.
2012-08-29 08:45:43.39 spid7s Directory lookup for the file "G:\MSSQL\Data\temp_MS_AgentSigningCertificate_database.mdf" failed with the operating system error 3(The system cannot find the path specified.).
2012-08-29 08:45:43.39 spid7s Error: 1802, Severity: 16, State: 1.
2012-08-29 08:45:43.39 spid7s CREATE DATABASE failed. Some file names listed could not be created. Check related errors.
2012-08-29 08:45:43.39 spid7s Error: 912, Severity: 21, State: 2.
2012-08-29 08:45:43.39 spid7s Script level upgrade for database 'master' failed because upgrade step 'sqlagent100_msdb_upgrade.sql' encountered error 598, state 1, severity 25. This is a serious error condition which might interfere with regular operation and the database will be taken offline. If the error happened during upgrade of the 'master' database, it will prevent the entire SQL Server instance from starting. Examine the previous errorlog entries for errors, take the appropriate corrective actions and re-start the database so that the script upgrade steps run to completion.
2012-08-29 08:45:43.39 spid7s Error: 3417, Severity: 21, State: 3.
2012-08-29 08:45:43.39 spid7s Cannot recover the master database. SQL Server is unable to run. Restore master from a full backup, repair it, or rebuild it. For more information about how to rebuild the master database, see SQL Server Books Online.
2012-08-29 08:45:43.39 spid7s SQL Trace was stopped due to server shutdown. Trace ID = '1'. This is an informational message only; no user action is required.
You'll see a similar error if the log folder is not set correctly:
2012-08-29 08:57:50.73 spid7s CREATE FILE encountered operating system error 3(The system cannot find the path specified.) while attempting to open or create the physical file 'F:\MSSQL\Logs\temp_MS_AgentSigningCertificate_database_log.LDF'.
2012-08-29 08:57:50.93 spid7s Error: 5123, Severity: 16, State: 1.
2012-08-29 08:57:50.93 spid7s CREATE FILE encountered operating system error 3(The system cannot find the path specified.) while attempting to open or create the physical file 'F:\MSSQL\Logs\temp_MS_AgentSigningCertificate_database_log.LDF'.
2012-08-29 08:57:50.93 spid7s Error: 1802, Severity: 16, State: 4.
2012-08-29 08:57:50.93 spid7s CREATE DATABASE failed. Some file names listed could not be created. Check related errors.
2012-08-29 08:57:50.93 spid7s Error: 912, Severity: 21, State: 2.
2012-08-29 08:57:50.93 spid7s Script level upgrade for database 'master' failed because upgrade step 'sqlagent100_msdb_upgrade.sql' encountered error 598, state 1, severity 25. This is a serious error condition which might interfere with regular operation and the database will be taken offline. If the error happened during upgrade of the 'master' database, it will prevent the entire SQL Server instance from starting. Examine the previous errorlog entries for errors, take the appropriate corrective actions and re-start the database so that the script upgrade steps run to completion.
2012-08-29 08:57:50.93 spid7s Error: 3417, Severity: 21, State: 3.
2012-08-29 08:57:50.93 spid7s Cannot recover the master database. SQL Server is unable to run. Restore master from a full backup, repair it, or rebuild it. For more information about how to rebuild the master database, see SQL Server Books Online.
2012-08-29 08:57:50.93 spid7s SQL Trace was stopped due to server shutdown. Trace ID = '1'. This is an informational message only; no user action is required.
Friday, June 22, 2012
The Distribution Agent for a Transactional Publication Will Ignore the MaxBCPThreads Setting by Default
The company I work for hosts a SaaS solution for multiple customers, and we utilize transactional replication to push a copy of the customer's data from our SQL servers to a SQL server on-site at the customer's location. This allows much greater reporting flexibility without impacting the performance of the production SQL Server.
We are currently migrating our largest customer to a new SQL server (which requires us to set up replication from scratch and generate/push a new snapshot to initialize the new transactional publications). By default, SQL Server ignores our setting for MaxBCPThreads in the Distribution Agent profile and will only push the BCP files serially. With this customer we have a large pipe between our data center and the customer's location (on the opposite coast), but serial snapshot delivery only allows us to consume about 10% of the available bandwidth (even with the maximum packet size option of -PacketSize 32767 in the command line of the Distribution Agent job).
In short, to address the issue we needed to recreate the publication and specify the sp_addpublication argument @sync_method = 'native'. However, the reason why is a bit obscure.
According to SQL Server 2005, 2008 and 2008 R2 Books Online, the default @sync_method is character for snapshot publications (non-concurrent character mode BCP output) and concurrent_c (concurrent character mode BCP output) for all other publication types. However, in my experience, the actual defaults are native (non-concurrent native mode BCP output) for snapshot publications and concurrent (concurrent native mode BCP output) for all other publication types. This is actually a good thing as the native SQL BCP snapshot format is faster/more efficient to deliver to the subscriber. The character formats are only necessary for publications with non-SQL Server publishers.
So what does this have to do with the snapshot delivery? In addition to affecting the snapshot generation, the concurrency setting also affects snapshot delivery at the subscriber. When using the concurrent sync_method, the Distribution Agent will ignore the MaxBCPThreads setting (in the Agent Profile) and deliver the BCP files in the snapshot serially. With smaller databases this is not a major issue. However, in my case, I'm trying to push snapshots that are around 100GB and serial delivery of the BCP does not take advantage of the amount of bandwidth we have between our site and our customer's site. From SQL Server Books Online: When applying a snapshot that was generated at the Publisher using the concurrent snapshot option, one thread is used, regardless of the number you specify for MaxBcpThreads.
By utilizing the native snapshot process (and increasing the MaxBCPThreads value from the default of 1 to 16), I can now push 16 BCP files simultaneously to the subscriber, thus taking full advantage of the large pipe between our site and our customer's site. There is no upper limit to what MaxBCPThreads can be set to, but you don't want to set it too high and overwhelm the CPUs on the distributor or subscriber. I've successfully tested 32 simultaneous threads on a system with only 16 cores (no hyper-threading).
Note: You cannot change the concurrency setting of a publication on the fly. You will need to drop and recreate the publication via a T-SQL script. You can use one of the following methods to script the publication creation:
We are currently migrating our largest customer to a new SQL server (which requires us to set up replication from scratch and generate/push a new snapshot to initialize the new transactional publications). By default, SQL Server ignores our setting for MaxBCPThreads in the Distribution Agent profile and will only push the BCP files serially. With this customer we have a large pipe between our data center and the customer's location (on the opposite coast), but serial snapshot delivery only allows us to consume about 10% of the available bandwidth (even with the maximum packet size option of -PacketSize 32767 in the command line of the Distribution Agent job).
In short, to address the issue we needed to recreate the publication and specify the sp_addpublication argument @sync_method = 'native'. However, the reason why is a bit obscure.
According to SQL Server 2005, 2008 and 2008 R2 Books Online, the default @sync_method is character for snapshot publications (non-concurrent character mode BCP output) and concurrent_c (concurrent character mode BCP output) for all other publication types. However, in my experience, the actual defaults are native (non-concurrent native mode BCP output) for snapshot publications and concurrent (concurrent native mode BCP output) for all other publication types. This is actually a good thing as the native SQL BCP snapshot format is faster/more efficient to deliver to the subscriber. The character formats are only necessary for publications with non-SQL Server publishers.
The default in SQL Server 2000 was native and according to SQL Server 2012 Books Online, the default has been changed back to native for all SQL Server publications.
So what is the difference between native and concurrent? Books Online indicates that utilizing the concurrent option "Produces native-mode bulk copy program output of all tables but does not lock tables during the snapshot." Whereas, the native option locks the tables for the duration of the snapshot generation. However, this is not the whole story. When using the concurrent option the tables are not locked for the entire duration of the snapshot generation, but the very last step of the Snapshot generation process is to lock the tables to capture the delta. This may still cause blocking (it does in our environment), but the impact should greatly reduced as the tables are locked for a much shorter period of time.
Note: You cannot change the concurrency setting of a publication on the fly. You will need to drop and recreate the publication via a T-SQL script. You can use one of the following methods to script the publication creation:
- Right-click the existing publication in SQL Server Management Studio and choose Generate Scripts... (I usually output to a new Query Editor window and then save the script once I've made the appropriate changes)
- Go through the GUI to set up the publication and choose Generate a script file with steps to create the publication (save the file to your hard drive and then open with SSMS once script generation is complete)
Once you have the script, change @sync_method = 'concurrent' to @sync_method = 'native'. You will also want to verify that any SQL Server authentication passwords are correct (for security purposes, SQL Server will not extract the passwords from the existing publication).
Resources used in my research to address this issue:
Resources used in my research to address this issue:
BOL SQL 2008 R2: http://technet.microsoft.com/en-us/library/ms188738(v=sql.105).aspx
BOL SQL 2012: http://technet.microsoft.com/en-us/library/ms188738.aspx
Greg Robidoux's very helpful post: http://www.mssqltips.com/sqlservertip/1270/transactional-replication-snapshot-issues-in-sql-server/
SQL Server Central post on the topic:http://www.sqlservercentral.com/Forums/Topic1129095-291-1.aspx
I'd specifically like to thank Hilary Cotter for providing a very swift answer to my dilemma. His contribution to the SQL Server community is greatly appreciated!
Friday, April 27, 2012
BCP Command Line Utility Installation Process
SQL Server 2012 BCP command line utility installation
Recently, I needed to install the BCP utility on our job automation servers. These servers do not need the full suite of SQL Server Workstation Tools, just the BCP.exe command line utility. I found the following process worked quite well at only installing what was needed (thus saving around 1 GB of disk space by not installing the Workstation Tools).
The following components need to be installed on a standalone server in order to get the BCP utility functioning.
- Windows Installer 4.5
- Be sure to download the appropriate version for your OS
- SQL Server 2012 Native Client (SQL Server 2008 R2 Native Client)
- The Native Client is about half way down the page
- Be sure to download the appropriate version for your OS
- SQL Server 2012 Command Line Utilities (SQL Server 2008 R2 Command Line Utilities)
- A little further down the same page as the Native Client
- Be sure to download the appropriate version for your OS
Since the servers I was dealing with were Windows Server 2003, I needed to install the Windows Installer 4.5. Newer versions of Windows Server (i.e. Windows Server 2008 R2) already have the newer Windows Installer. If installation of the Windows Installer is needed, a reboot will be required.
Installing the Native Client and Command line utilities are as simple as just running the installers. A reboot is not required for either the Native Client or Command Line Utilities.
These instructions are specifically for the SQL Server 2012 (and 2008 R2) BCP utility, but should be able to be adapted for other versions of SQL Server
That's it! Once the aforementioned components are installed, the command line BCP utility should work beautifully.
That's it! Once the aforementioned components are installed, the command line BCP utility should work beautifully.
Wednesday, April 25, 2012
Replication Troubleshooting - How to deal with out of sync publications
Transactional Replication and nasty errors that cause out of sync publications.
The other day we had an issue on our distributor that caused deadlocks on the Distribution database. Several of the Log Reader Agents suffered fatal errors due to being chosen as the deadlock victim. This caused the following error to occur:

After much searching on the error, I came across several forum posts that indicated I was pretty well up a creek. I then found this post on SQLServerCentral. Hilary Cotter's response was the most beneficial for devising a recovery plan and Stephen Cassady's response helped me refine that plan.
Hilary Cotter (Blog) is an expert when it comes to SQL replication. He certainly knows his stuff!
The Recovery Plan
Recovering from this issue involves several steps.
For small databases or publications where the snapshot to reinitialize the publication will be small and push quickly, it's simplest and best to just reinitialize the entire publication and generate/push a new snapshot.
For larger publications (my publication contained almost 1,000 tables) and situations where pushing the snapshot will take an inordinate amount of time (24+ hours in my case) the following process can be used to skip the missing transactions and identify the tables that are now out of sync:
Log Reader Agent Recovery
The simplest way to recover the Log Reader Agent is to run the following command against the published database:
Subscription Validation
Validating the Subscription(s) is a fairly straightforward task.
Identify out of sync tables
I created the following script that will return the tables that failed validation:
-- This script will return out of sync tables after a Subscription validation has been performed
-- Set the isolation level to prevent any blocking/locking
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT
mda.publication [PublicationName],
mdh.start_time [SessionStartTime],
mdh.comments [Comments]
FROM distribution.dbo.MSdistribution_agents mda
JOIN distribution.dbo.MSdistribution_history mdh ON mdh.agent_id = mda.id
-- Update Publication name as appropriate
WHERE mda.publication = 'My Publication'
AND mdh.comments LIKE '%might be out of%'
-- This next line restricts results to the past 24 hours.
AND mdh.start_time > (GETDATE() - 1)
-- Alternatively, you could specify a specific date/time: AND mdh.start_time > '2012-04-25 10:30'
-- View most recent results first
ORDER BY mdh.start_time DESC
I hope this helps if you run into the same situation. I would like to especially thank Hilary Cotter for sharing his knowledge with the community as his forum and blog posts really helped me resolve the issue.
The other day we had an issue on our distributor that caused deadlocks on the Distribution database. Several of the Log Reader Agents suffered fatal errors due to being chosen as the deadlock victim. This caused the following error to occur:
- The process could not execute 'sp_repldone/sp_replcounters' on 'MyPublisherServer'
- The specified LSN (%value) for repldone log scan occurs before the current start of replication in the log (%newervalue)
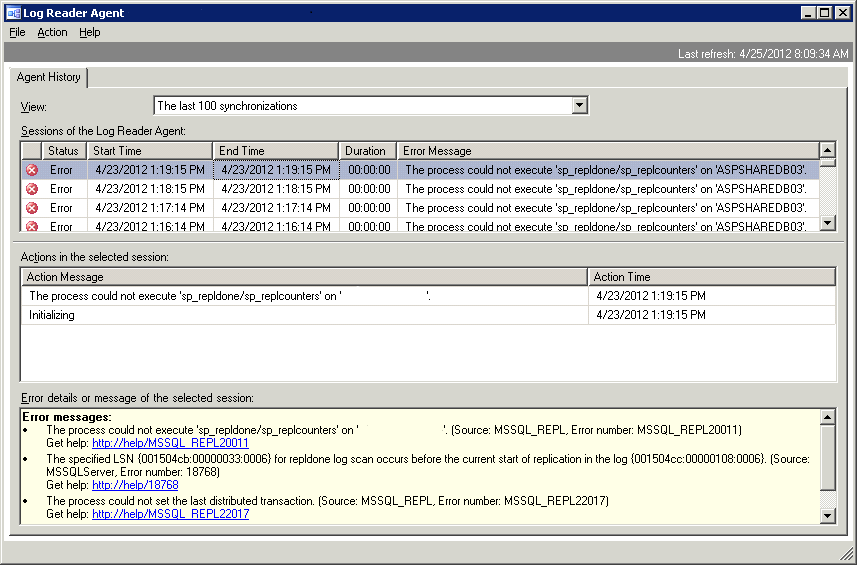
After much searching on the error, I came across several forum posts that indicated I was pretty well up a creek. I then found this post on SQLServerCentral. Hilary Cotter's response was the most beneficial for devising a recovery plan and Stephen Cassady's response helped me refine that plan.
Hilary Cotter (Blog) is an expert when it comes to SQL replication. He certainly knows his stuff!
The Recovery Plan
Recovering from this issue involves several steps.
For small databases or publications where the snapshot to reinitialize the publication will be small and push quickly, it's simplest and best to just reinitialize the entire publication and generate/push a new snapshot.
For larger publications (my publication contained almost 1,000 tables) and situations where pushing the snapshot will take an inordinate amount of time (24+ hours in my case) the following process can be used to skip the missing transactions and identify the tables that are now out of sync:
- Recover the Log Reader Agent by telling it to skip the missing transactions
- Recover the Distribution Agent by configuring it to ignore data consistency issues
- Validate the publication to determine which tables are out of sync
- Drop and republish out of sync tables
Log Reader Agent Recovery
The simplest way to recover the Log Reader Agent is to run the following command against the published database:
- sp_replrestart
This effectively tells SQL to restart replication NOW, thus ignoring all transactions that have occurred between the time of the failure and the time you run the command. The longer you wait to run this command, the more activity in the database that gets ignored, which likely results in more tables that fall out of sync.
Distribution Agent Recovery
Now that the Log Reader Agent is capturing transactions for replication, the Distribution Agent will likely get upset because there are transactions missing. I specifically received the following error:- The row was not found at the Subscriber when applying the replicated command
- Launch Replication Monitor
- In the left-hand column
- Expand the DB server that contains the published database
- Select the Publication
- In the right-hand pane
- Double-click the Subscription
- In the Subscription window
- Go to the Action menu and select Agent Profile
- Select the profile: Continue on data consistency errors. and click OK
- Be sure to note which profile was selected before changing it so that you can select the appropriate option once recovery is complete
- If the Distribution Agent is currently running (it's likely in a fail/retry loop), you'll need to:
- Go to the Action menu and select Stop Distribution Agent
- Go to the Action menu and select Start Distribution Agent
- If there is more than one subscription, repeat these steps for any additional subscriptions
Subscription Validation
Validating the Subscription(s) is a fairly straightforward task.
- Launch Replication Monitor
- In the left-hand column of Replication Monitor
- Expand the DB server that contains the published database
- Right-click the Publication and select Validate Subscriptions...
- Verify Validate all SQL Server Subscriptions is selected
- Click the Validation Options... button and verify the validation options - I recommend selecting the following options:
- Compute a fast row count: if differences are found, compute an actual row count
- Compare checksums to verify row data (this process can take a long time)
- Once you are satisfied with the validation options, click OK and then click OK to actually queue up the validation process
- Please note: for large databases, this process may take a while (and the Validate Subscriptions window may appear as Not Responding)
For my publications (~1,000 tables and DB was ~100GB) the validation process took about 20 minutes, but individual results will vary.
If you wish to monitor the validation progress
- In the right-hand pane of Replication Monitor
- Double-click the Subscription
- In the Subscription window:
- Go to the Action menu and select Auto Refresh
Identify out of sync tables
I created the following script that will return the tables that failed validation:
-- This script will return out of sync tables after a Subscription validation has been performed
-- Set the isolation level to prevent any blocking/locking
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT
mda.publication [PublicationName],
mdh.start_time [SessionStartTime],
mdh.comments [Comments]
FROM distribution.dbo.MSdistribution_agents mda
JOIN distribution.dbo.MSdistribution_history mdh ON mdh.agent_id = mda.id
-- Update Publication name as appropriate
WHERE mda.publication = 'My Publication'
AND mdh.comments LIKE '%might be out of%'
-- This next line restricts results to the past 24 hours.
AND mdh.start_time > (GETDATE() - 1)
-- Alternatively, you could specify a specific date/time: AND mdh.start_time > '2012-04-25 10:30'
-- View most recent results first
ORDER BY mdh.start_time DESC
The Comments column will contain the following message if a table is out of sync:
- Table 'MyTable' might be out of synchronization. Rowcounts (actual: %value, expected: %value). Checksum values (actual: -%value, expected: -%value).
Make a list of all tables that are returned by the aforementioned script.
Now the determination needs to be made as to the level of impact.
- The Reinitialize All Subscriptions option should be used if the following is true:
- Large number of tables affected (majority of published tables)
- Unaffected tables are small in size (if the snapshot for the unaffected tables is going to be very small, it's much easier to just reinitialize everything)
- Dropping and re-adding individual tables should be used if the following is true:
- The number of tables affected is far less than the total number of tables
- The tables that are unaffected are very large in size and will cause significant latency when pushing the snapshot
The latter was the case in my scenario (about 100 out of 1,000 tables were out of sync, and the ~900 tables that were in sync included some very large tables).
Reinitialize All Subscriptions
Follow this process if the determination has been made to use the Reinitialize All Subscriptions option:
Recover out of sync tables
If the determination has been made to recover the individual tables, use the list of tables generated from the validation process and follow this process:
Follow this process if the determination has been made to use the Reinitialize All Subscriptions option:
- In the left-hand column of Replication Monitor
- Expand the DB server that contains the published database
- Right-click the Publication and select Reinitialize All Subscriptions...
- Verify Use a new snapshot is selected
- Verify Generate the new snapshot now is NOT selected
- Click the Mark For Reinitialization button
- Please note: for large databases, this process may take a while (and the Replication Monitor window may appear as Not Responding)
- In the right-hand pane of Replication Monitor
- Select the Agents tab (in SQL 2005 select the Warnings and Agents tab)
- Right click the Snapshot Agent and select Start Agent
- The reason for performing this manually is that sometimes when you select the Generate the new snapshot now option, it kicks off the Snapshot Agent before the reinitialization is complete which causes blocking, deadlocks and major performance issues.
Recover out of sync tables
If the determination has been made to recover the individual tables, use the list of tables generated from the validation process and follow this process:
- In the left-hand column of Replication Monitor
- Expand the DB server that contains the published database
- Right-click the Publication and select Properties
- Select the Articles page in the left-hand column
- Once the center page has populated, expand each table published to determine if the table is filtered (i.e. not all columns in the table are published).
- If tables are filtered, make a note of the columns that are not pushed for each table
- Once review of the tables is complete, click Cancel
- If you click OK after expanding tables, it will invalidate the entire snapshot and you will end up reinitializing all articles in the publication
- Right-click the Publication and select Properties
- Select the Articles page in the left-hand column
- Clear the check boxes for all out of sync tables and click OK
- Right-click the Publication and select Properties
- Select the Articles page in the left-hand column
- Select the affected tables in the center pane
- If any tables were not completely replicated, be sure to reference your notes regarding which columns are replicated
- Click OK when table selection is complete
- Note: If you receive an error that the entire snapshot will be invalidated, close the Publication Properties window and try adding in a few tables at a time until all tables are selected.
- In the right-hand pane of Replication Monitor
- Select the Agents tab (in SQL 2005 select the Warnings and Agents tab)
- Right click the Snapshot Agent and select Start Agent
- Double-click the Subscription
- Go to the Action menu and select Auto Refresh
Final cleanup
Once the snapshot has been delivered and replication has caught up on all queued transactions, perform the following to return replication to a normally running state.
- In the left-hand column of Replication Monitor
- Expand the DB server that contains the published database
- Select the Publication
- In the right-hand pane of Replication Monitor
- Double-click the Subscription
- In the Subscription window
- Go to the Action menu and select Agent Profile
- Select the profile that was configured before you changed it (if unsure, the Default agent profile is typically the default) and click OK
- If there is more than one subscription, repeat these steps for any additional subscriptions
I hope this helps if you run into the same situation. I would like to especially thank Hilary Cotter for sharing his knowledge with the community as his forum and blog posts really helped me resolve the issue.
Subscribe to:
Posts (Atom)